2024年是至強的大年。
先于6月正式發布的至強® 6700E系列開啟了全新的、更為簡潔命名方式:至強® 6能效核。144核的規格也意味著英特爾在最近幾年當中首次在核心數量方面實現了領先。而且,這還并不是至強6的最強形態,畢竟大家都知道還有個6900P系列嘛。
9月26日,至強6這個“最強形態”終于正式發布,主要規格非常震撼。即使面對今年內晚于自己發布的其他廠商同級別CPU,至強® 6900P的已有規格也戰力十足。

英特爾代號Birch Stream的新一代服務器平臺所采用的至強6處理器是分批次發布的。6月發布的是代號Sierra Forest的能效核處理器6700E系列(E后綴即Efficiency Core,能效核的標記),目前發布的是代號Granite Rapids的性能核6900P系列。今年底和明年初還會陸續發布6900E、6700P,以及6500/6300等。未來的Intel 18A制造工藝的處理器,如Clearwater Forest,也會繼續用于Birch Stream平臺。
至強6900P是英特爾專為計算密集型工作負載設計的處理器,也是Granite Rapids的“完全體”。后綴的“P”意味其采用的是Performance Core,即性能核,規模大、性能強;6900的數字型號則說明其核心配置拉滿——提供了72到128核的多種規格,TDP有400W和500W兩種,組合成已公開5種型號,顯得比較簡潔。當然,依照慣例,云廠商等大客戶還會有若干定制型號的。單就內核數量而言,6900P系列相對前兩代“Rapids”產品線頂配的56/60(Sapphire Rapids)或64核(Emerald Rapids)直接翻倍!如此巨大的迭代幅度非常罕見,也難怪英特爾要改命名方式了,由表及里都透著一個意思:厚積薄發、脫胎換骨!
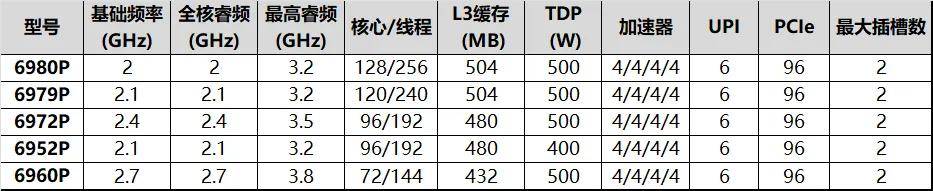
尤為值得一提的是:至強6900P也是業內首款性能核數量正式“破百”的產品,其他同級產品,不論是x86架構還是Arm架構都只達到了96核的水平。它們的性能核數量要追平英特爾,起碼得等到下個季度。
隨著內核規模增加,至強6900P的L3緩存達到了504MB。為了配合倍增的核數和顯著提升的算力,至強6900系列的存力也大為增強,內存帶寬方面不僅支持12通道DDR5 6400;并引入了新型內存MR DIMM,把數據率大幅提升至8800MT/s,基本內存帶寬可以達到第五代至強可擴展處理器的2.3倍。另外,至強6還支持CXL 2.0,尤其是包括Type 3設備(也就是CXL內存),可以進一步擴展內存容量和帶寬。
至強6900P的UPI2.0鏈路也有很大改進,速率提升到24GT/s,數量增加至6條,使得雙路互聯效率進一步提升。結合內核數量、內存帶寬等方面的全面提升,至強6900P可以被視作高算力+高存力平臺的最強機頭,不論是科學計算,還是AI集群。根據已透露的測試,至強6900P平臺的數據庫、科學計算等關鍵應用負載的表現是上一代產品的2.31倍-2.5倍,AI應用性能是其1.83倍-2.4倍不等。


至強6的擴展能力也有不小的提升。其中6900系列單插座不論是性能核還是能效核均可提供96通道PCIe 5.0,雙路即可提供192通道PCIe 5.0。未來上市的6700系列單路型號可以提供136通道PCIe 5.0,雙/多路型號單插槽也可以提供88通道。相較而言,第四、五代至強可擴展處理器的PCIe 5.0通道數量為80。CXL支持能力方面,至強6 6900、6700系列都支持64通道CXL 2.0。
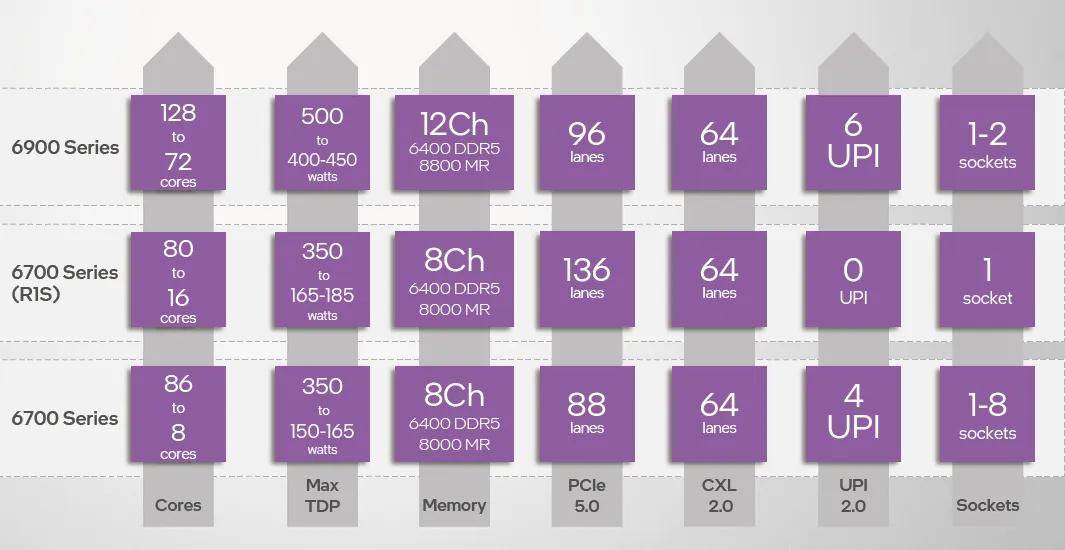
更多的內核、更多的內存通道、更多的PCIe通道需要更大規模的插座接口支持。 至強6帶來了兩種接口:LGA 4710和LGA 7529。至強6900系列使用面積較大的LGA 7529插座,提供最強大的內存帶寬和擴展能力,是未來高性能、高密度服務器的基礎。至強6700以及未來的6500/6300系列使用LGA 4710,尺寸與第四、五代至強的LGA 4677相仿,內存、PCIe的通道數相同或相近,有利于主流服務器內部布局習慣的延續性。
核心規模的飆升首先得益于至強產品線終于獲得EUV光刻機的加持。在2023年發布的酷睿Ultra已經率先使用了引入EUV的Intel 4制造工藝。而2024年發布的至強6則使用了進一步改良的Intel 3制造工藝。
2021年7月,英特爾CEO帕特·基爾辛格公布了“四年五個制程節點”(5N4Y)的工藝路線圖。Intel 3的量產時間節點位于2023年底,節奏基本符合計劃。從基于Intel 4制造工藝的酷睿Ultra的市場表現看,EUV的加持確實明顯提升了英特爾處理器的競爭力。至強6所采用的Intel 3制造工藝相對Intel 4可以規劃更多的金屬層、擁有更多細分版本。

Intel 3在更多的步驟中應用EUV光刻,可以提供更密集的設計庫、更高的晶體管驅動電流。Intel 3還有三種變體,包括3-T、3-E和3-PT。Intel 3、3-T是基本工藝,主要用于CPU;3-E是功能擴展;三者都支持TSV;Intel 3的這三種變體與Intel 4相比可以提升18%的性能功耗比。而3-PT進一步增加混合鍵合的支持能力,帶來了更高的性能并且易于使用。Intel 3所有四種節點變體都支持240 nm高性能和210 nm高密度庫,而Intel 4只支持240 nm高性能庫。
對于性能取向,Intel 3針對高性能運算進行優化,可以支持低電壓(<0.65V)和高壓(>1.3V)運行,且在各電壓下的頻率均高于Intel 4。

至強6900P采用的性能核微架構代號Redwood Cove。Redwood Cove也是近年來英特爾最重要的微架構迭代,不但給服務器產品線帶來了新名字,在消費類產品線同樣開啟了新的命名序列酷睿Ultra。
我們先快速回顧一下Redwood Cove的上一代Golden Cove/ Raptor Cove。Golden Cove其實也是非常重要的迭代,在消費類開啟了大小核時代(第12代酷睿處理器),在服務器上就是第四代至強可擴展處理器。Golden Cove相對其前代的微架構大幅度提升了前端:
Golden Cove的后端當然也有提升,譬如重排序緩沖區、分支目標緩沖區也有大概30%左右的提升,只是相對前端幅度不那么大。
Raptor Cove的微架構與Golden Cove差異不大,表現在實際產品上主要是緩存的提升,如基于Raptor Coved的第13代酷睿(Raptor Lake)的每核心L2緩存從12代(Alder Lake)的1.25MB提升到2MB;第五代至強可擴展處理器(Emerald Rapids)和第四代(Sapphire Rapids)每個核心的L2緩存都是2MB,但前者每個網格的末級緩存(Last Level Cache,也可繼續俗稱為L3緩存)從后者的1.875MB猛增到5MB。
Redwood Cove相對Golden Cove/ Raptor Cove的最重要變化是:
當然,Redwood Cove還有一個重大的優勢就是“命好”,也就是前面提到的EUV制造工藝。但即使有革命性的制造工藝加持,至強6性能核也沒過分擴張每個內核的規模。就至強6性能核的內核而言,每個網格節點是一個P核,每個P核配置私有的2MB L2緩存,以及共享的4MB 末級緩存。雖然平均到每個核的緩存容量并不比上一代至強(Emerald Rapids)多,但勝在總核數翻倍后。至強6性能核每個處理器可共享的末級緩存總容量依舊達到504MB,遠超第五代的320MB和第四代的112.5MB。
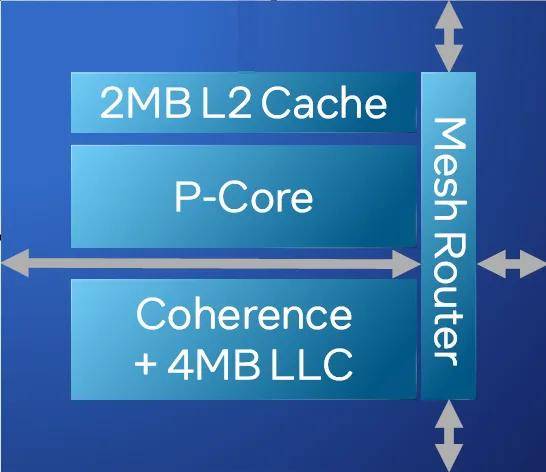
在此也順便提一下至強6能效核的微架構Crestmont。這個微架構同樣出現在了酷睿Ultra的能效核當中。Crestmont是2或4個內核為一組共享L2緩存。在至強6能效核當中,每2或4個內核與4MB的L2緩存(在酷睿Ultra中則為2MB)構成一個模塊,這幾個內核共享頻率和電壓域。這個模塊對應的網格還擁有可整個處理器全部內核共享的3MB的末級緩存。換句話說,雖然至強6能效核的核數更多,但實際上網格規模比至強6性能核小。

能效核的指令緩存與性能核都是64KB,但數據緩存分別是32KB和48KB。前端的指令解碼器寬度也有差異,分別為6和8寬。指令亂序執行引擎差異較大,能效核是256條而性能核是512條。能效核不支持性能核所支持的AVX-512和AMX,這也可以明顯減小矢量運算單元的晶體管占用,但代價是每周期的單精度浮點運算次數有了數量級的差異。但能效核也改進了AVX2,增加了VNNI的INT8和BF16/FP16快速轉換,這樣在處理AI應用的時候表現也還有所改善。另外,其256位加密和1024/2048密鑰也獲得了能效核的支持,確保至強6平臺的安全水平基本一致。

緩存規模、前端寬度以及矢量單元的差異,使得至強6性能核和能效核有不同的定位。早先發布的至強6能效核更適合微服務等運算強度相對較輕,可在高核心數量和規模擴展方面收益的任務,以追求更高的能效、更高的機架利用率。而現在發布的至強6性能核更適合大數據、建模仿真等計算密集型和人工智能任務,為高性能優化,單顆處理器的功耗直飚500W——當然,跟同期發布的Gaudi AI加速器的新品或類似的加速器產品相比,能耗是應有的代價,有能力提升性能上限才是正經事。
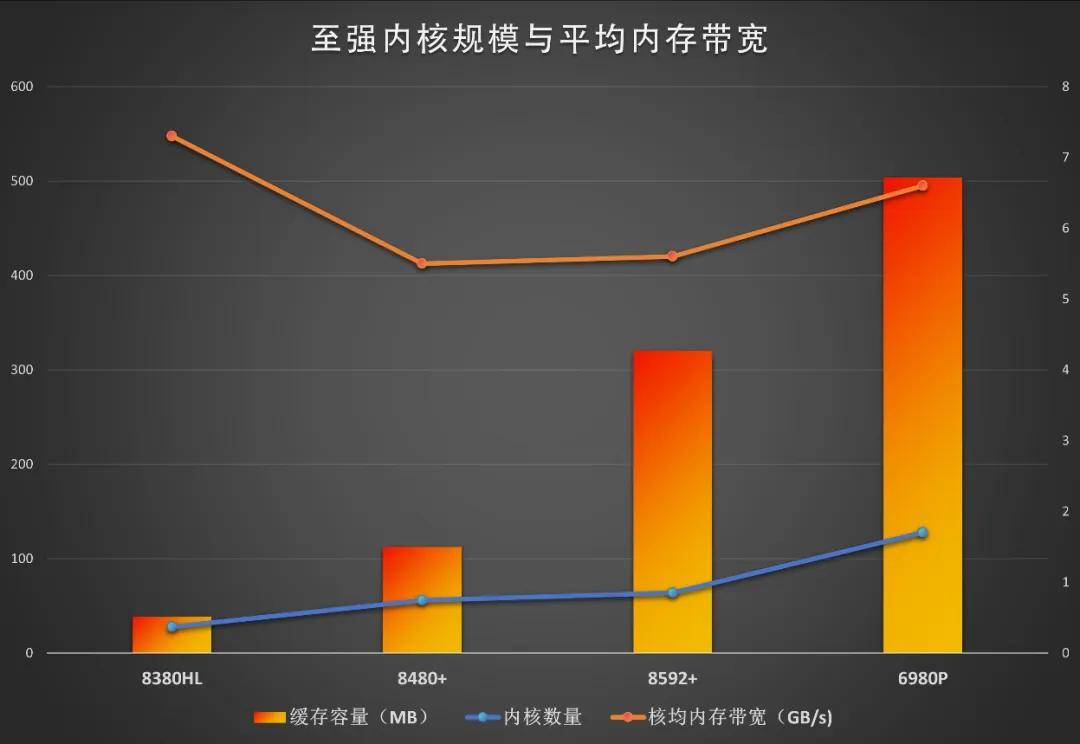
內存(DRAM)的數據存儲依賴電容,這個特點使其微縮和提速的難度大于晶體管。因此內存并沒有沾摩爾定律的光,帶寬和密度的增長落后于CPU、GPU的發展。內存帶寬滯后于CPU內核數量的增長導致一個長期問題:平均每個內核的內存帶寬增長乏力,甚至出現倒退。譬如第三代至強可擴展處理器內核數28,內存是八通道DDR4 3200,理論上的內存總帶寬為205GB/s,平均每核7.3GB/s;四代是56或60核,內存八通道DDR5 4800,總帶寬307GB/s,平均每核5.5GB/s;五代提升到DDR5 5600,內核再增加到64,平均帶寬改進甚微。第四、五代至強可擴展處理器雖然引入了新一代的DDR5內存,但由于內核數量相對三代翻倍,內存帶寬的增長幅度還是跟不上。同時期其他廠商的CPU核數在屢屢躍進的過程當中也存在同樣的問題。為了彌補內存帶寬增長較慢的問題,第四代至強可擴展處理器給部分用于科學計算的型號引入了HBM,五代則大幅度增加了末級緩存的容量,并支持CXL 2.0內存擴展。
在至強6900P上,內存問題終于得到了比較好的解決。這涉及三個角度:
1.大容量末級緩存。前面提到過,6900P每個網格提供4MB L3,總容量達到了504MB,分別是四代的4.5倍、五代的1.6倍。而且,至強的全網格架構使得任意內核訪問末級緩存的延遲相比其他廠商的一些產品有更優的表現,例如不需要跨計算單元而造成延遲劇增。這種架構效率更高的優勢也是至強在核數曾落后的情況下還能打的有來有往的關鍵原因。
2.DDR5內存雙管齊下提升帶寬。至強6900系列支持12通道DDR5 6400,總帶寬可以達到614GB/s,平均每核的帶寬大致還有5GB/s的水平。6900P還支持新型內存MRDIMM,頻率提升至8800MT/s,總帶寬達到了845GB/s,平均每核6.6GB/s,也明顯超過了前兩代產品,大幅度逆轉了內核數量增加、平均內存帶寬不升反降的問題。
MR(Multiplexed Rank)DIMM打開了DDR內存性能提升的新方向。DRAM通常由1到2個Rank組成,每個Rank的位寬為64位,如果考慮ECC,那就會有72或80位,但有效的數據是64位。消費類內存(UDIMM)可能只有1個Rank(顆粒數量較少的情況下),但追求大容量的服務器內存(RDIMM)基本上都至少有2個Rank。在以往的內存模式當中,一次只讀取一個Rank的數據,另一個Rank暫時閑置時可以做刷新操作,以保持數據——這種輪流讀取、刷新Rank的特點延續了多年。MRDIMM設計了一個數據緩沖區,通過將兩個內存Rank分別讀入這個緩沖區,再從緩沖區一次性傳輸到CPU的內存控制器,由此實現了帶寬翻倍。第一代DDR5 MRDIMM的目標速率為8800 MT/s,其實每個Rank只相當于4400MT/s。現在DDR5 6400已經開始普及,因此MR DIMM的第二階段目標是達到12800 MT/s,預計在2030年代的三代會提升至17600 MT/s。
3.CXL 內存擴展。第四代至強可擴展處理器開始引入CXL支持,當時是1.1版本,暫時也沒有公開支持Type 3設備(也就是CXL內存)。從第五代開始正式引入了CXL 2.0,包括Type 3,可以幫助擴展內存容量和帶寬。在至強6上,CXL設備的應用將更為普及,關鍵的CXL2.0標準設備,以及后向兼容的CXL1.1設備,預計都會陸續涌現。
這里重點說一下CXL內存的優勢。CXL2.0支持鏈路分叉,使一個主機端口可以對接多個設備,而且提供更強的CXL內存分層支持,可實現容量和帶寬擴展。至強6支持3種CXL內存擴展模式:CXL Numa Node、CXL Hetero Interleaved、Flat Memory。

在CXL Numa Node模式下,系統的標準內存和CXL擴展內存被視為兩個獨立的Numa節點進行控制。每個Numa節點都有自己的內存地址空間,系統軟件或應用程序可以將任務分配到不同的Numa節點,從而優化內存的使用。CXL Numa Node模式適用于需要精細內存管理的應用,可以通過操作系統、虛擬機管理程序(Hypervisor)或應用程序本身來輔助分層管理內存。
Hetero Interleaved(異構交織)模式通過將系統的標準內存和CXL內存混合在一起,形成一個統一的Numa節點。每個內存地址空間中的數據可以交替存儲在DRAM和CXL內存中,從而均衡內存帶寬,減少延遲。異構交織模式適用于對內存帶寬有高需求的應用,特別是當需要將DRAM和CXL內存結合使用時。此模式只有在配備性能核的至強6700P、6900P上才支持。假設將每顆至強6900P的64通道CXL用滿,可以額外增加256GB/s的內存帶寬,單處理器就可以實現TB級的內存帶寬,還是相當可觀的。
Flat Memory(平面內存)模式下,CXL內存和標準內存被視為單一的內存層,操作系統可以直接訪問統一的內存地址空間。硬件輔助的分層管理可以確保常用數據優先存儲在標準內存中,次要數據存儲在CXL內存中,從而最大限度地提升內存使用效率。平面內存模式最大的價值在于無需修改軟件即可利用CXL內存擴展,而且這種模式適用于所有的至強6處理器。但平面內存模式要求標準內存和CXL內存是1:1配置,這略為限制了硬件采辦、升級的靈活性。整體而言,平面內存模式是至強6時期最易用、收效最直觀的模式,有望成為CXL內存擴展的主要模式。
至強6是至強家族首次將計算和IO芯片獨立,再通過Chiplet形式封裝在一起,總算是把高級封裝的優勢真正發揮出來了。
第四代至強可擴展處理器是英特爾的首個Chiplet設計的至強處理器。其XCC版本內部是4顆芯片通過10組EMIB對等連接,每顆芯片提供15個內核、2通道內存控制器、1組加速單元,以及UPI、PCIe PHY若干。另外,還可以通過EMIB封裝4顆HBM。
第五代至強可擴展處理器使用2顆芯片封裝而成,所使用的EMIB數量明顯減少,相應地也節約了芯片面積。雖然內核數量略有增加,但也損失了UPI、PCIe的數量,也不再能夠搭配HBM。
隨著制造工藝演進,偏重計算性能和晶體管密度的處理器內核,與偏重高速信號互聯的IO控制器對制造工藝的要求產生了差異,因此,典型的Chiplet設計將計算和IO分離,分別應用不同的制造工藝。英特爾在14代酷睿上便采用了這種方式,分為Compute Tile、SoC Tile、IO Tile、Graphic Tile。代號Ponte Vecchio的英特爾Data Center GPU Max利用Foveros和EMIB技術,將47個小芯片封裝在一起,包括Compute Die、Base Die、Rambo、IO Die等。
至強6終于也拆分成計算單元(Compute Tile)和IO單元(IO Tile),分別由Intel 3和Intel 7工藝制造。
計算單元
根據收集到的信息,對于能效核,目前只出現了一種計算單元的設計,每個單元最多提供144個內核、4組內存控制器共八通道;對于性能核,則是有三種計算單元的設計,可分別用于組合高核數、中等核數、低核數的規格。
至強6900P使用了三個計算單元,每個單元43個內核、兩個內存控制器,總共構成129個內核(只使用128個)和12個內存通道。這種計算單元姑且稱之為單元A,三個單元A構成的處理器被稱為UCC。

未來發布的6700P核數跨度會很大,其中單路型號規劃為16~80核,多路型號為8~86核。單元A有4個內存通道,兩個單元A組合可以提供最高86核,下限應該不低于48核(否則屏蔽的內核數量就實在太多,也太浪費EMIB成本),這種規模的處理器被稱為XCC。48核以下的中等核數被稱為HCC,使用一種專門開發的單元B,每個單元提供48個內核和4個內存控制器。HCC核數的下限預計在24核左右。8和16核的6700P被稱為LCC,需要使用第三種單元C,16個內核和4個內存控制器。

通過使用3種計算單元進行組合,至強6性能核可以構建跨度從8~128核的、非常綿密的規格。也許會有人認為,相比其他廠商只用一種規格計算單元實現擴展的設計,英特爾需要設計三顆不同的芯片的成本會更高。但我認為,這是英特爾優先考慮性能的結果。首先,至強6將內存控制器安排在計算單元中,離內核更近,延遲更低,即使因此犧牲了單元組合使用的靈活性也是值得的。其次,至強6性能核給不同規模的內核數量規劃不同的網格規模,有利于降低核間的延遲,甚至,有可能LCC會針對較低的核數改用環形總線。綜上,預計至強6性能核相對同等規模的其他廠商的產品依舊可能會擁有內存延遲低、緩存延遲低的優勢。
IO單元
IO單元方面,至強6900、6700系列都使用2顆相同的IO芯片。每個IO芯片由2個IO模塊、4個UIO模塊、2個加速器模塊,以及IO網絡接口構成。每個IO模塊提供x16 PCIe或CXL連接;每個UIO模塊提供x24 UPI2.0,或復用為x16的PCIe或CXL;每個加速器模塊提供DSA、IAA、QAT、DLB加速器各一個。
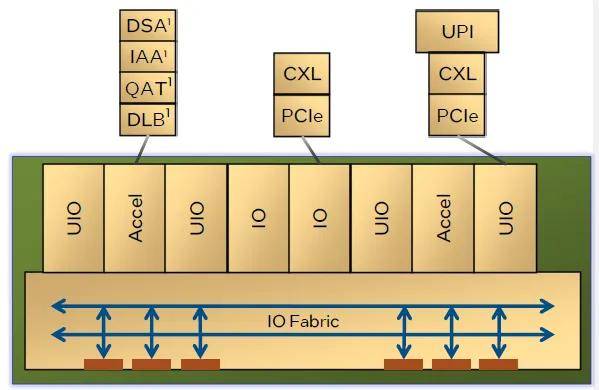
以這次發布的至強6900P為例,兩個IO單元總共提供8個UIO和4個IO模塊。其中6組UIO負責提供6個UPI2.0互連,剩余的2個UIO和4個IO模塊正好提供6×16=96通道的PCIe 5.0。雙路至強6900P的UPI不但速率高(24GT/s,高于五代的20GT/s和四代的16GT/s),連接數量也提升了50%。
對于還未發布、也是主力產品的至強6700系列,估計由于要使用規模較小的插座,只提供最多4組UPI用于多路的互聯,PCIe通道也有所縮減。但即使如此,至強6700系列的單路型號在將所有UIO配置為PCIe之后,單插槽就可以提供多達136個PCIe通道,或64通道CXL。如果用單路至強6700配合半寬主板構建雙節點服務器,那一個機箱內的PCIe/CXL擴展能力(272 /128)遠遠超過已知的任何雙路服務器。這種機箱可能會成為新的池化形態,可以更高的密度提供NVMe存儲、CXL內存、加速器等。
結 語
由于英特爾在14nm到10nm制造工藝的迭代過程遇到了一些問題,以致此前幾代至強平臺在“核戰”(比拼核數)中略顯被動,但這個局面在至強6上有望完全逆轉。改良后的EUV制造工藝看來沒有束縛至強6的實力,核心數量、緩存容量、內存帶寬等關鍵指標全都進入領先行列,一句話總結就是算力和存力的表現全部拉滿。至強6900P系列在各種項目的測試當中,其代際性能提升就都是以倍數計,而非百分之十幾、幾十的進步。這種形勢也使得英特爾得以全面競爭科學計算、大數據、AI等領域的性能王座。
此外,至強6終于實現計算與IO的解耦,也讓至強6及未來的產品線走上了正確、靈活的道路,得以充分發揮Chiplet的優勢。將Chiplet視作降低成本、提高良率的手段是狹隘的。Chiplet的價值在于靈活、復用、重構。英特爾長期以來很注重細分市場的耕耘,產品線非常復雜,正確利用Chiplet可以達到事半功倍的效果。我們非常期待至強6后續產品的陸續發布能夠給業界帶來什么樣的想象力。返回搜狐,查看更多
提示:文章內容僅供閱讀,不構成投資建議,請謹慎對待。投資者據此操作,風險自擔。


